
MCP工具,提供了三个
以json的格式,让AI来管理记忆
可以添加记忆,搜索记忆,删除记忆。
运行的效果
先让AI记住
再在一个 新对话 里让AI回忆
工作流的逻辑
实际上是让AI使用MCP工具,和Postgres向量数据库进行有限的交互
添加记忆:
{
"user_id": "繁星",
"memory_text": "繁星喜欢哥特风服装"
}
返回:
[ { "result": "记住了" } ]
查询记忆:
{
"user_id": "繁星",
"query": "喜欢什么服装"
}
查询记忆需要对数据库输出的内容进行预先格式化:
const searchResults = $input.all();
// 如果 PGVector 结果为空
if (searchResults.length === 0) {
return [{
json: { result: "不记得了呢" }
}];
}
// 过滤掉 pageContent 为空的项
const validResults = searchResults.filter(item => {
const doc = item.json.document;
return (
doc &&
typeof doc.pageContent === 'string' &&
doc.pageContent.trim().length > 0
);
});
// 如果全是空内容,也返回“不记得了呢”
if (validResults.length === 0) {
return [{
json: { result: "不记得了呢" }
}];
}
// 映射成你想要的最终数组结构(一个 item 输出一个 json 对象)
return validResults.map(item => {
const doc = item.json.document;
return {
json: {
user_id: doc.metadata.user_id,
memory_text: doc.pageContent.trim(),
time: doc.metadata.time,
score: item.json.score
}
};
});
返回(向量相似性最接近的5条):
[
{
"user_id": "繁星",
"memory_text": "喜欢的颜色是 黑色 暗红色 还有紫色",
"time": "2025-09-01T16:59:13.216Z",
"score": 0.3429950671495451
},
{
"user_id": "繁星",
"memory_text": "喜欢哥特风的衣服,各种华丽的王子系Lolita,以及各种斗篷",
"time": "2025-09-01T17:05:16.204Z",
"score": 0.36613168221319414
}
]
删除记忆
{
"user_id": "繁星",
"time": "2025-09-01T17:05:16.204Z"
}
一些细节问题
因为我用的是n8n搭建工作流的方法,所以也是有不少的限制
1.n8n自带的mcp节点下面,有个将子工作流作为工具的节点,这个很方便,因为只需要在里面选择子工作流就可以变成一个mcp的工具,不用自己考虑数据传输的问题
坑点:不支持异步操作,比如如果想先返回结果给AI,之后在工作流里继续做其他流程就实现不了
解决:直接用http request 和 webhook 来搭建工作流(相当于需要自己解决数据交互的问题)
2.n8n的数据库节点,不能获取到row的uuid,导致没法让AI精确操作某一条数据
解决:用code节点,写了个js(当然是AI写的),在添加记忆的时候,自动给json的数据里添加一个 time 时间戳 和传入的user_id以及memory_text一起写到数据库的metadata列里
在获取记忆的时候,将time时间戳也加入到返回的数据中,这样就可以让AI根据user_id和time来删除记忆了。
async function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
let output = [];
for (const item of $input.all()) {
let data = item.json;
if (Array.isArray(data)) {
for (const d of data) {
await sleep(5); // 延迟 1 毫秒
output.push({
json: {
...d,
time: new Date().toISOString()
}
});
}
} else {
await sleep(5); // 延迟 1 毫秒
output.push({
json: {
...data,
time: new Date().toISOString()
}
});
}
}
return output;
3.如何解决记忆冲突问题
假如,今天记下了喜欢打英雄联盟,10天后又记下了 讨厌英雄联盟 ,那需要一个机制能自动删除更早的记忆。
工作流如图
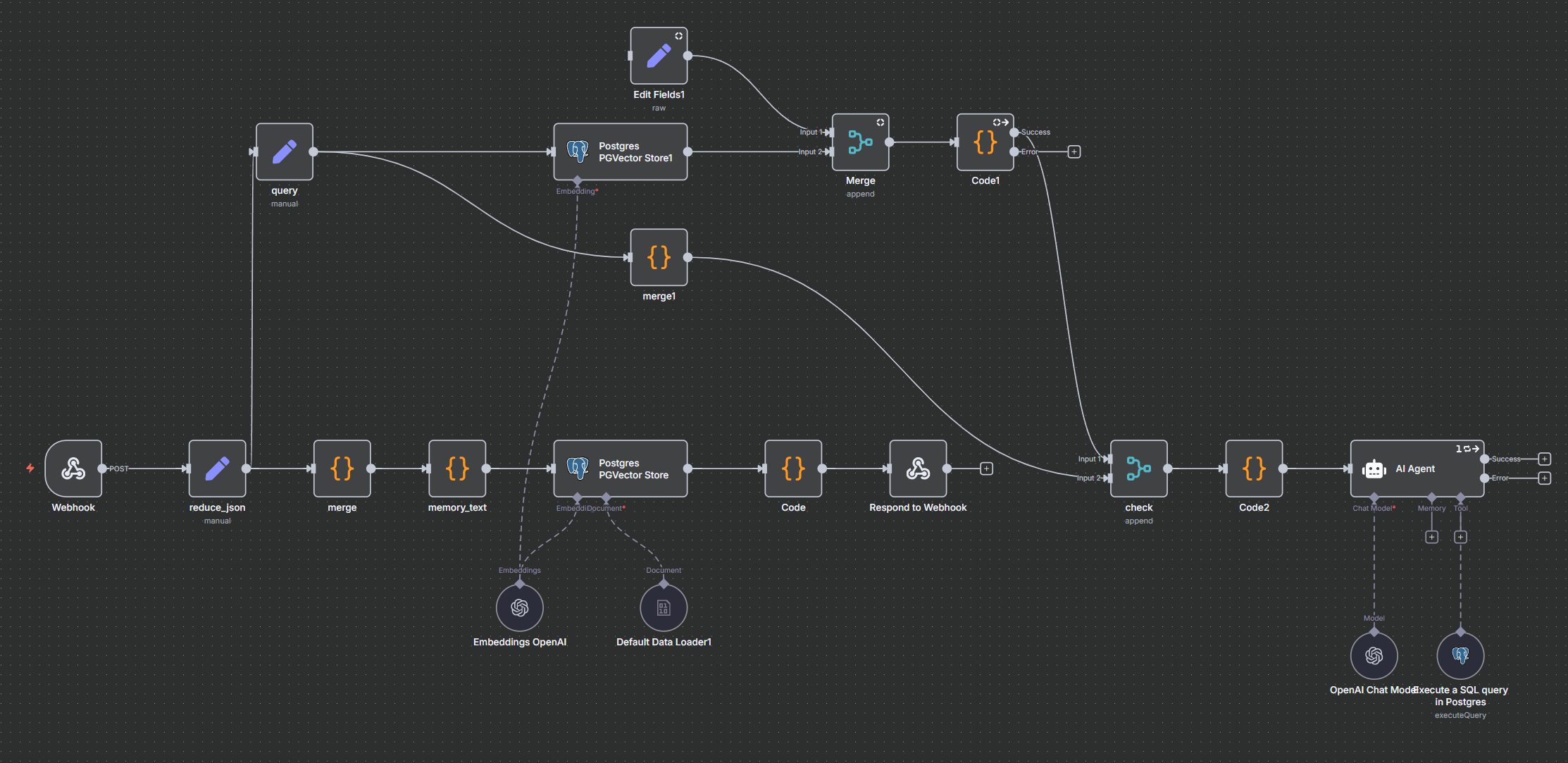
这个操作放在添加记忆的时候进行,因为这样查询数据库的成本最低,如果之后再查,那需要把整个数据库里的内容都丢给AI让其进行全面整理,当记忆比较多的时候就很费劲了。
我的逻辑是:当添加记忆的时候,用添加的新记忆去查询数据库里已经有的记忆,然后丢给一个Agent来判断是否有冲突,如果有,就调用数据库工具删除旧的记忆。
下面webhook的部分就是正常的添加记忆并返回数据,而上面那部分就是查询数据库并让一个便宜的模型(我现在用的是 Gemini-2.5-flash-lite)来检查冲突。
需要先将要输入给AI Agent的数据转移到一个单一的json对象内:
// 把上一个节点的所有 json 数据提取出来
const cleaned = items.map(i => i.json);
// 直接输出数组到 prompt,不再 stringify
return [
{
json: {
prompt: cleaned
}
}
];
Agent的提示词
你是一个Postgress记忆数据库管理员。
你需要读取输入给你的所有数据按一下步骤执行。
阅读记忆数据:
user_id 和 time 是数据库中的metadata,用于选定表中的行。
query里的内容是新增的记忆。
memory_text里的内容是以前的记忆。
执行逻辑检查:
判断新增的记忆和以前的记忆(可能有一个或多个)是否有逻辑和事实上的冲突。
检查逻辑冲突时,需要根据time考虑时间因素。
除非认为两个记忆之间有关联且有冲突才应该考虑删除(比如喜欢的颜色 和 晚上吃了什么之间显然没任何联系,不能算做冲突)
操作数据库:
如果有冲突,则用你的数据库工具删除冲突的记忆。
如果没有冲突,不调用数据库工具。
SQL示例:
DELETE FROM memory
WHERE (metadata->>'user_id', metadata->>'time') IN (
('用户ID', '2025-09-01T09:53:13.797Z'),
('用户ID', '2025-09-02T10:00:00.000Z')
);
最后:
如果要使用工具,则在使用工具之后回复“冲突已解决”。
如果无需使用工具,就回复“无冲突”。
为什么要做这种事情
我试了能找到的一些可以给AI提供记忆功能的MCP服务器,但是都不好用或者无法部署。
因为我的需求是:
必须在lobechat服务器版里用,所以MCP必须支持HTTP流的协议(lobechat只支持这个) – 大多数都只能SSE
支持自然语言搜索记忆 – 好多是用的树状图还是什么,总之本质就是一个数据库里面一堆分层的json,一旦让AI回忆,AI就找不到记忆了,因为AI只会用自然语言搜索,除非写一个非常复杂的提示词,不然每次回忆都得读取整个图表 (也可能是我不会用)
但愿我这玩意用一段时间没翻车 2333, Lobechat什么时候才出原生的记忆功能啊!


![Win10桌面版体验[安装篇]](https://3efs.com/wp-content/uploads/2015/05/win10-exp-install.jpg)
