配置软件
AnimateDiffusion是一款用于StableDiffusion的视频生成插件,要安装这款插件,你需要使用下面的链接,在SdWebUI中安装插件。
在SDWebUI中,选择 【扩展】-> 从网址安装 -> 扩展的Git仓库网址
对硬件的需求为:5~12GB显存,推荐8GB显存。
还需要下载生成视频的配套Lora和运动模型。
motion_module
从列表中下载 mm_sd15_v3.safetensors ,然后将其放入
你的SDWebUI根目录\extensions\sd-webui-animatediff\model 目录下。
motion_lora
在下载列表的Lora目录下,有一些助于控制画面运动的Lora,使用方法和普通的Lora无异。
更新显卡驱动
使用新的NvidiaAPP程序更新显卡驱动到最新(这个相比原来的GeforceExperience来说,免登录 而且运行速度更快)
https://www.nvidia.cn/software/nvidia-app/
优化选项
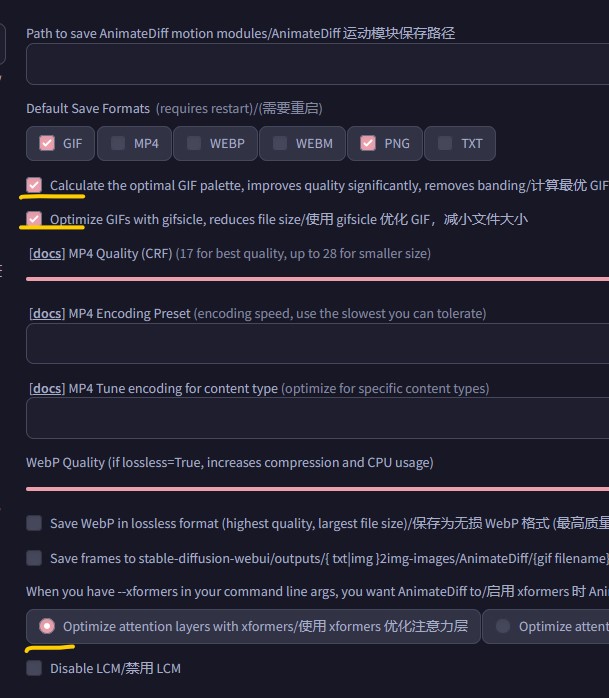
需要注意的是,使用之前,在插件设置选项里,选择以上的优化选项 – 非必选项。(前两个是用来优化GIF图片效果的,第三个可以优化显存占用)
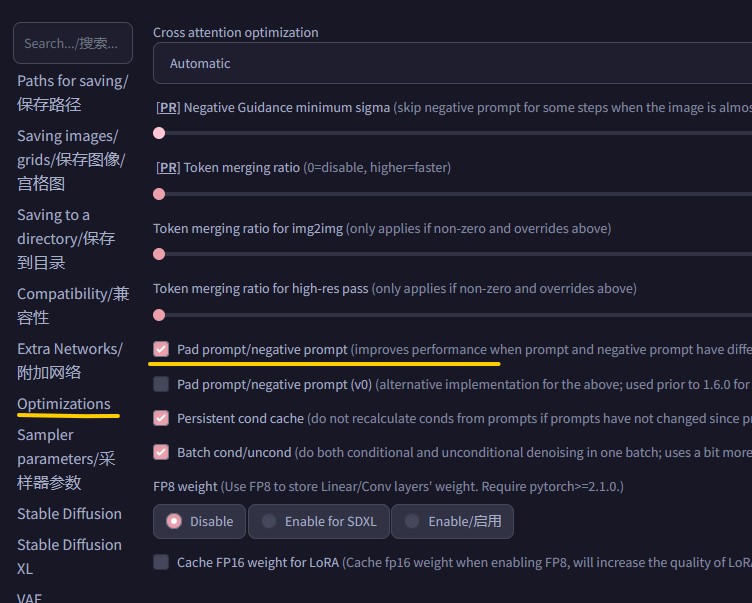
然后需要在 优化(Optimizations)选项里,启用 自动补全正反提示词长度 – 推荐使用此配置。
用下面第二个选项也可以,第二个根据描述是更好的方法,启用第二个会覆盖第一个的效果。
生成视频
生成图片参考
在生成视频之前,可以先按照常规的图片生成方法,来获得满意的图片生成风格,和提示词的组合。
需要注意的是,正向提示词和反向提示词,都应该保持精简,尽量不超过75个词(原始上限)。
当我们获取到满意的图片之后,需要将种子值(seed)进行固定,并保持提示词和分辨率(比例)不变。
不过因为AI生成的随机性,即使固定了参数,每次生成的图片也将会有所不同。
启用视频生成
勾选启用AnimeteDiff选项即可启用视频生成,之后需要选择动画模型,动画模型就是配置的时候下载的那个运动模块
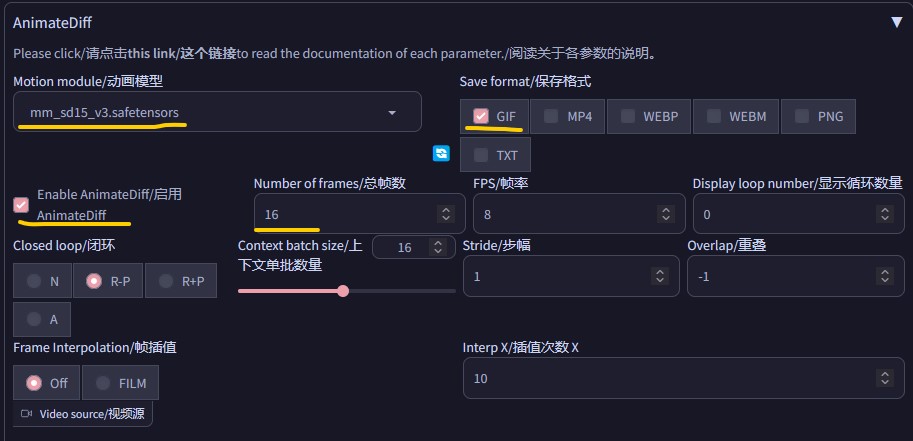
其他选项则按照需要进行配置,建议不要将 总帧数 和 FPS 设置的过高,如果设置的太高会导致生成速度非常慢 ,或者无法生成(可能会爆显存)
由于视频生成模型是使用16张图为一组进行训练的,因此,尽量保持 上下文单批数量 为 16 (默认值)。
步幅 和 重叠 选项也保持默认即可(通常情况下默认效果最佳)。
闭环 选项可以控制视频的循环,从N 到 A 对应的是循环的严格程度(N为不循环,A为强制循环)。
帧插值 可以通过插帧算法,提高生成视频的帧速率,可以让视频变的更流畅(直接提高 帧率 也可以,但是相比插帧这会需要更多的时间来计算)
之后只需要和生成图片一样,点击 生成 按钮,等待即可获得一个动态的GIF。
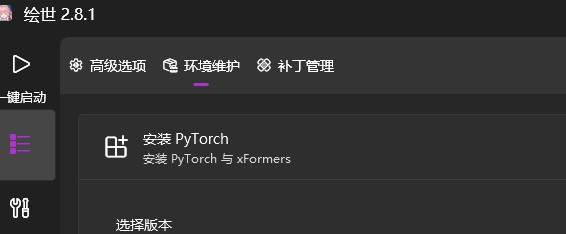
如果生成之后没有自动将图片变成视频,而是生成了一组图片,则需要安装 PyTorch+xFormers 这两个组件(选择最新版本),使用启动器的话,可以在启动器里找到安装选项。