StableDiffusion是一个开源的AI图形生成软件,通过不同的模型,它不仅可以生成手绘风格的图像,也能生成照片写实风格的图像。这篇教程将简短明了的描述如何安装和使用这个方便的工具。
部署软件
推荐使用启动器部署和管理Stable Diffusion。从下面的链接下载启动器。
先安装 dotnet-6.xxxx.exe,这是一个运行环境。
接下来将 sd-webui-aki.xxx.7z 解压缩到某个地方,建议是放在固态硬盘里使用,这样加载模型的速度会比较快。
最后下载controlnet 文件夹里的所有内容,并根据文件夹里安装教程里视频安装controlnet插件,这是一个对AI图像生成进行精准控制的插件。
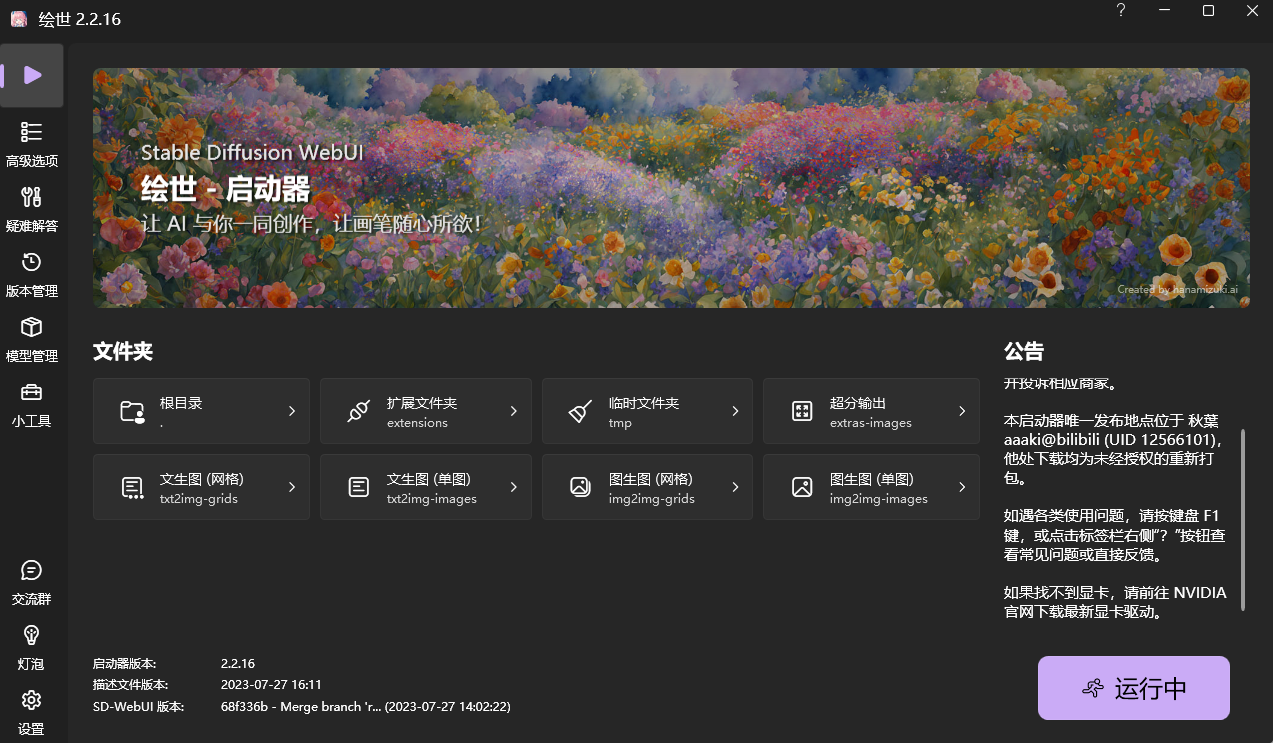
一切就绪之后,通过 sd-webui-aki.xxx 目录下的 启动器.exe 启动,界面如下。
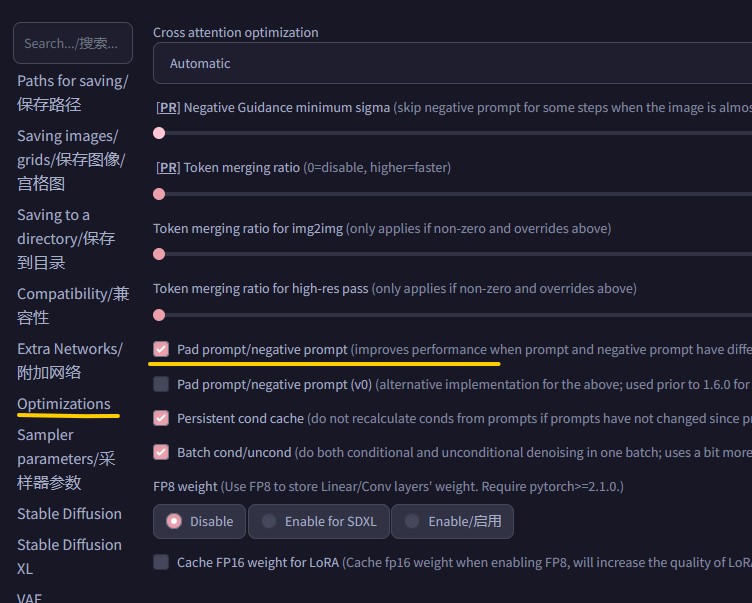
如果你的显卡显存大于8GB,则无需额外设置即可使用,如果你的显卡显存低于8GB,则需要在 高级选项 中,启用显存优化。
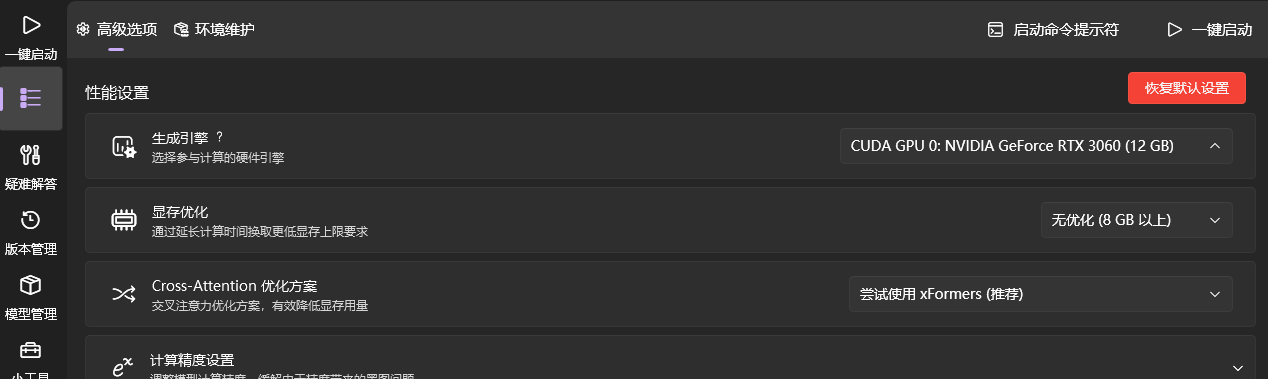
软件默认只提供了基础模型和基础插件,为了使用方便和实现更好的效果,强烈推荐下载和安装一些额外的模型和插件。
模型下载可以在以下几个网站获取:
civitai.com
esheep.com
liblibai.com
下载模型和插件
模型分为几种类型,常用是有三种
1.checkpoints
这就是通常所说的模型,决定了生成图像的整体风格和品质。
2.lora
这是一种辅助小模型,与 checkpoints 搭配使用,用于对画面的一些特征进行控制,比如,让生成的所有人脸都是某一类长相,或者让衣服是某一类风格,或让画风偏向某种风格等。
3.Embedding
这是文本辅助集合,可以简单理解为是一个 提示词 的合集,使用embedding可以节约很多重复的提示词撰写工作,比如 控制质量的那些正面提示词 和 负面提示词 (每次都会写,并且都差不多是一样的词)。
下载好各种东西之后,可以在模型管理界面,点击右上角添加模型到软件的路径下,启动器会自动识别模型的类别,并将其放置在对应的正确路径下。

插件安装需要先启动软件,然后在浏览器的webUI中操作。
启动后,点击 扩展 Extensionk 选项卡,点击 从URL安装 Install from URL 子选项卡,复制下面的网址,点击安装,等待安装完成即可。(由于代码都在Github这一海外网站,因此在不用代理的情况下可能会安装缓慢 或者失败,可以多试几次)。
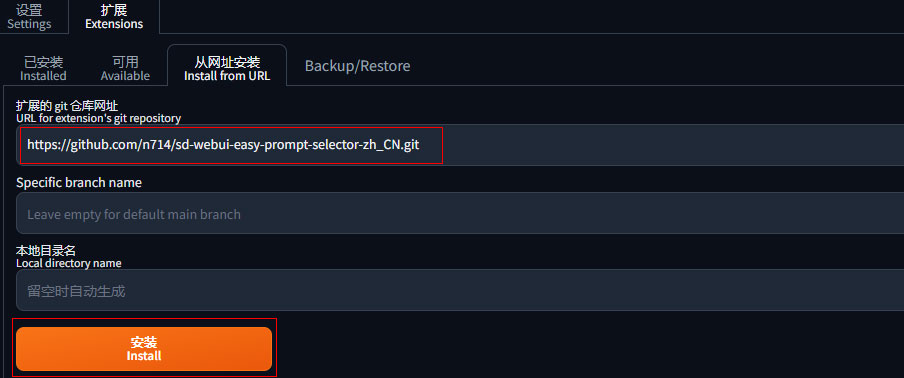
安装好之后,点击 扩展 Extensionk 选项卡,点击 应用并重启用户界面 Restart UI,等待软件重启即可。
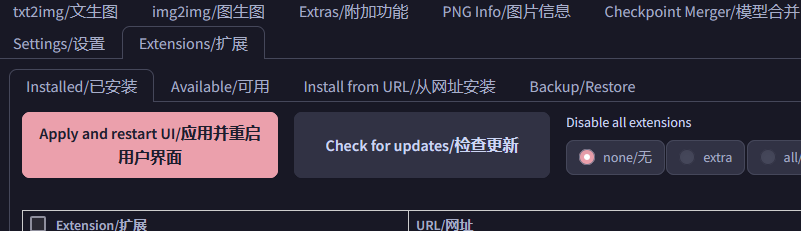
需要自己安装的插件主要是提示词辅助插件,这里推荐两个插件:
提示词库插件
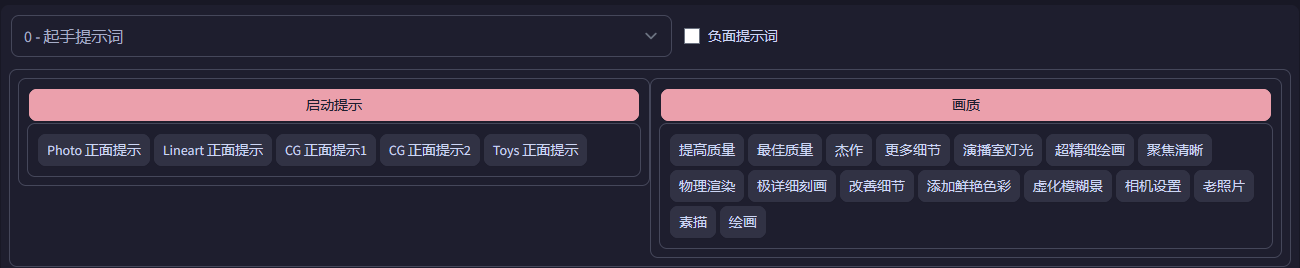
https://github.com/n714/sd-webui-easy-prompt-selector-zh_CN.git
提示词自动翻译插件
https://github.com/Physton/sd-webui-prompt-all-in-one.git
开始AI绘画
用AI生成高品质图片需要的步骤一般是以下几个:
纯文本生成图片
选择合适的 checkPoints模型 -> 选择合适的lora(可选)-> 输出 正向和负向提示词 -> 设置需要的图片分辨率 -> 设置采样方法和CFG(提示词相关性) -> 点击生成,等待图片计算完成
之后如果对图片不满意,就在点击生成一张新的,因为这个过程随机性比较强,所以也被戏称为抽卡。
根据图片生成图片
准备好用的图片,将其导入webUI中,接下来的步骤其实和文本生成图片没什么区别。
图片生成图片的时候,需要格外注意你要生成的图片的比例和你准备的原始图片的差异,一般推荐让他们保持相同比例,但是AI无法直接生成分辨率高的图像,因此推荐使用 根据原图缩放的功能设置生成分辨率。
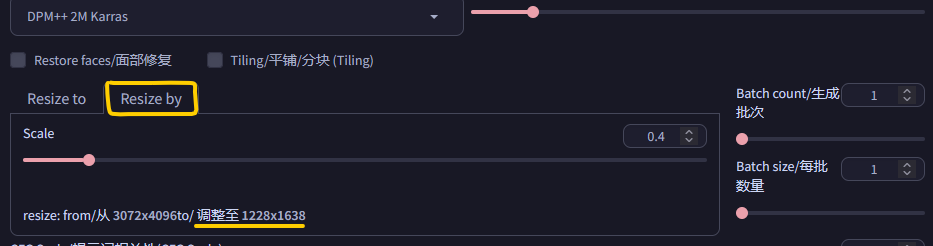
解释各个参数的设置
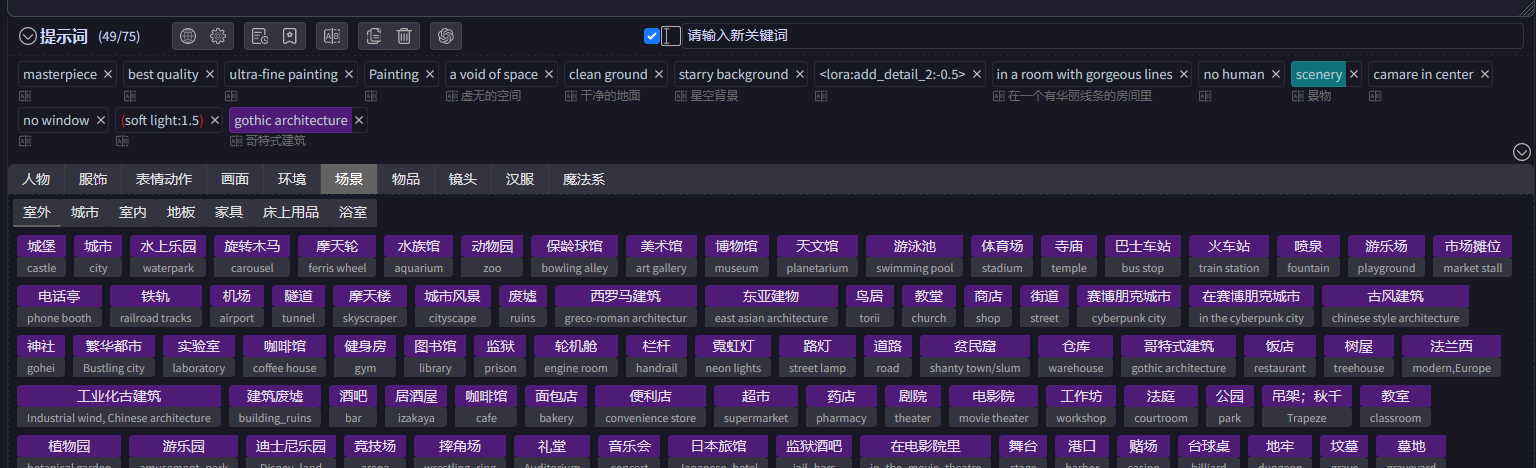
1.提示词
提示词的作用是,向AI描述你需要的图像的样貌,细节,特点,这样软件才能知道你想要怎样的图片。正向提示词就是你需要的特点,负面提示词就是你不需要的特点。
提示词可以是一个单独的单词,也可以是一个简短的句子,目前只支持用英文,可以使用安装的 中文翻译插件,直接输入中文提示词。
提示词之间必须用英文逗号分隔。
提示词有权重大小之分,越靠近左侧的提示词权重越大,因此最重要的内容应该首先写进去,也可以通过标记的方式人为提高某个提示词的权重大小,格式是 (masterpiece:1.2) 这样的,冒号之后的数字表示权重提高的比例。
一般来说,需要在提示词里加入质量控制词语来保证输出的图片是高品质的,可以用安装的插件来快速添加这些词。

点击插件按钮,会展开插件的UI,在里面根据需要选择就可以。

这里的主要区别是你想要生成的图像的风格,一般分为几种类型: 绘画,实拍,CG(三维渲染)
而负面提示词可以使用 embedding 来快速添加,点击下图按钮,展开模型库。
点击你想要使用的那一个,就可以将其添加入负面提示词框中。
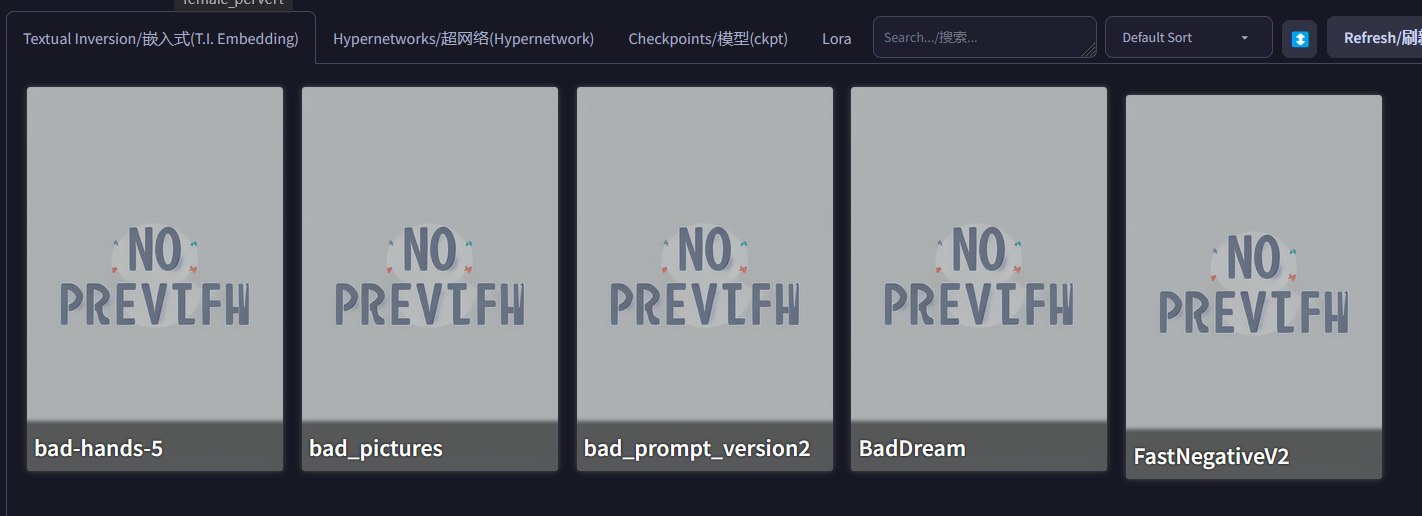
注意,如果你一次性点击了多个,软件有的时候不会自动给多个词之间添加逗号,需要手动添加一下。

同理,你可以用这种方式添加 lora 到你的提示词中,lora一般只用于正向提示词。
和普通的提示词一样,这些表示模型的提示词也能手动控制权重,例如:<lora:add_detail_2:0.5>
2.采样方法
采样方法决定了AI以何种算法生成图像,不同的采样方法会表现出不同的性格倾向性。
一般我常用的就是 Euler a (更多变和富有创造力),以及 DPM++ 2M Karras (更贴近提示词)。
图片后期处理
由于AI目前无法直接生成高分辨率的图像,或者由于你的硬件配置不足以直接生成高质量的图像,你只能先以较低的分辨率生成图像,然后再通过后期处理的方法放大图像,获得最后的高质量高分辨率图像。
生成图片之后点击 发送到附加功能 Send to extras 就可以将图片发送到后期处理UI中。
一般在这里只需要调整2个参数,缩放比例 和 算法。
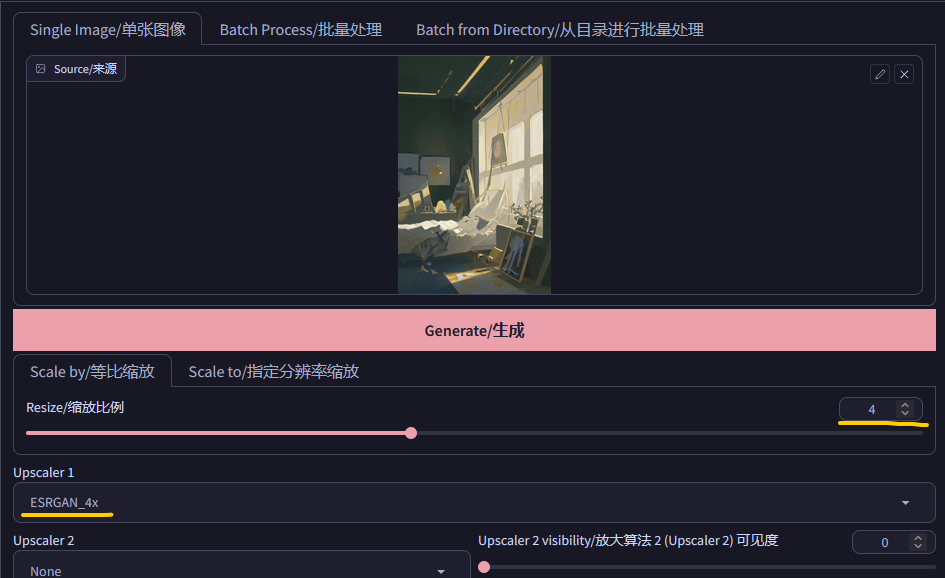
缩放比例就是你要将原图放大的倍数,而算法就是不同的放大计算方案,不同的算法对于不同风格的图片有显著的品质差异,因此可以多尝试几次按需选择。
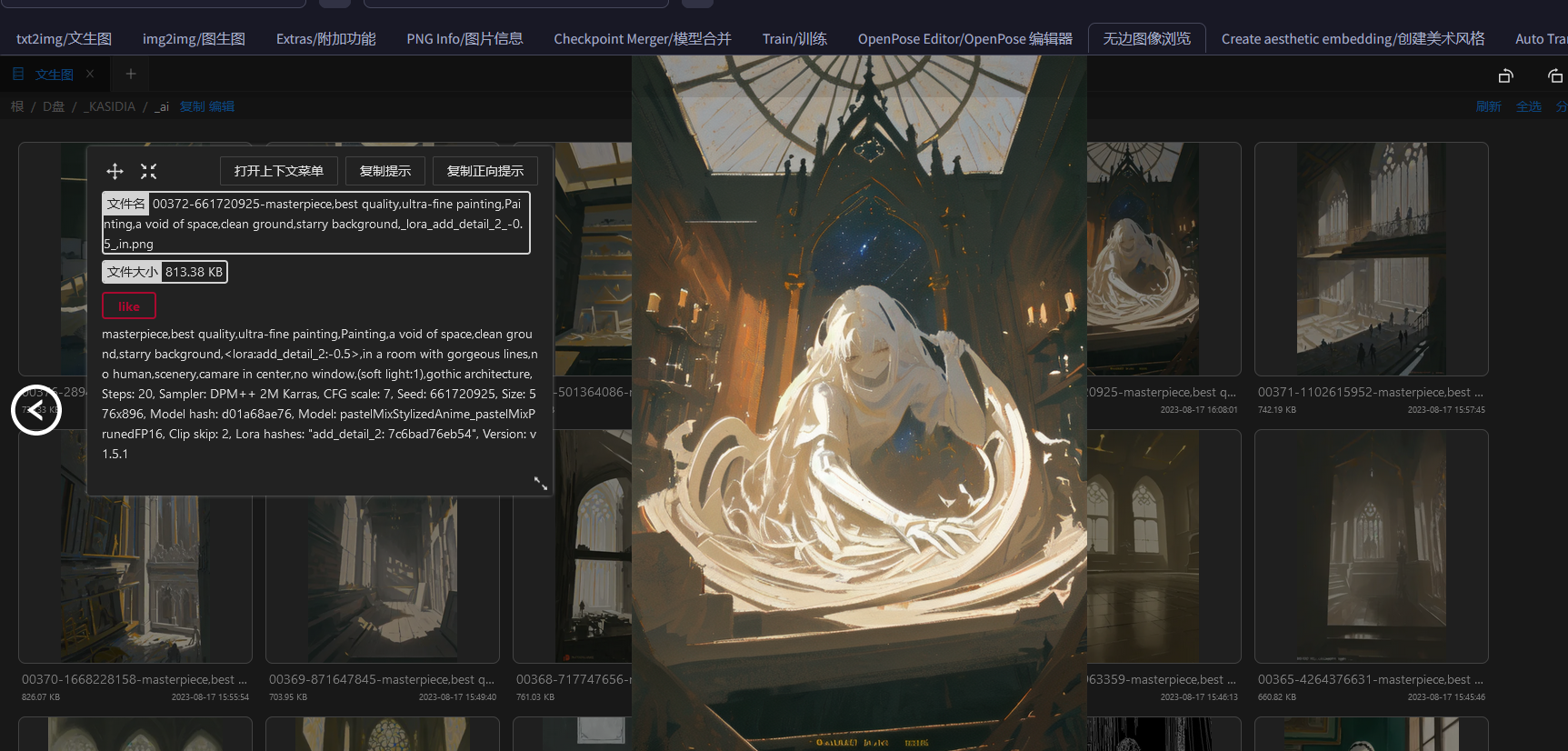
使用 图片浏览 功能,可以找到你之前生成的所有图片,并且可以查看那些图片使用的提示词和参数设定,也可以直接将某张图发送到其他模块继续处理。